Automating Translation Workflows
by David Bacisin, published
When I joined the Globalization team at Fetch in the spring of 2021, I had never written software to support multiple languages—but our team of 5 was tasked with driving the entire organization to become bilingual in English and Spanish.
Fortunately, our team lead had experience building translation workflows at a Fortune 100 company, and we worked closely with him to build upon his past experience. One of our projects was to develop a system to which other engineering teams could programmatically send translation requests and from which they would automatically receive completed translations.
Principles
We built our system around several core principles:
- Equity: people who prefer to use the app and interact with the company in Spanish deserve the same respect and attention to detail as those who prefer English. This also means that no feature should be launched in any one language until the content has been translated and the experience has been localized for every supported language.
- Quality: human translators far exceed the quality of machine translation, and the time and cost of an in-house translation team are well worth the result. If you’ve ever used automatic translation software, you know how quickly meaning can be mangled or how awkward the result can be. With an in-house team, we maintain a consistent style and voice as well as the ability to adapt quickly to business needs.
- Reliability and Performance: translatable content is everywhere, from the mobile app and website to the support pages and notification emails. To have a performant and reliable system, translated content must live as close as possible to where it will be displayed. The translation system must not be a single point of failure for any of these touchpoints, so a centralized content database is untenable for production operation. Instead, our central database provides redundancy—a backup if other backups fail.
With these principles to guide us, we dove into the project.
Build or Buy?
The classic question, should we build or buy a Translation Management System (TMS)? Commercial TMS’s provide translator-friendly interfaces, assistive tools like AI, task and review management, among many other features. Building our own would take a significant amount of time and effort. On the other hand, it would allow us to customize perfectly to the company’s needs.
With the desired timeline, we took a hybrid approach: build a thin system that would allow teams to submit requests and receive results, but would connect to a commercial TMS-as-a-service to provide our translators with the many features that would accelerate their productivity. Our system would also offer a stable interface to insulate other teams from making changes if we ever decided to switch to or add a new TMS.
Version 1.0
With these constraints, I designed a system using technologies that were firmly established within the Fetch engineering organization: Go, PostgreSQL on RDS, Elastic Beanstalk, SQS, and SNS.
Because it takes time for human translators to translate, edit, and review content, the system needed to be fully asynchronous. I proposed that teams could submit translations onto an AWS SQS messaging queue, made easier with a helper library that hid the internals of SQS. A worker process—running in a goroutine on a Beanstalk-based microservice—would pick up messages and forward them to the TMS. Once the translators completed their work, the TMS would notify a webhook served by the same microservice, which would pull the completed translations and broadcast them on an SNS topic for the requesting team to ingest. The microservice would also save a backup copy of the translation in a PostgreSQL instance.
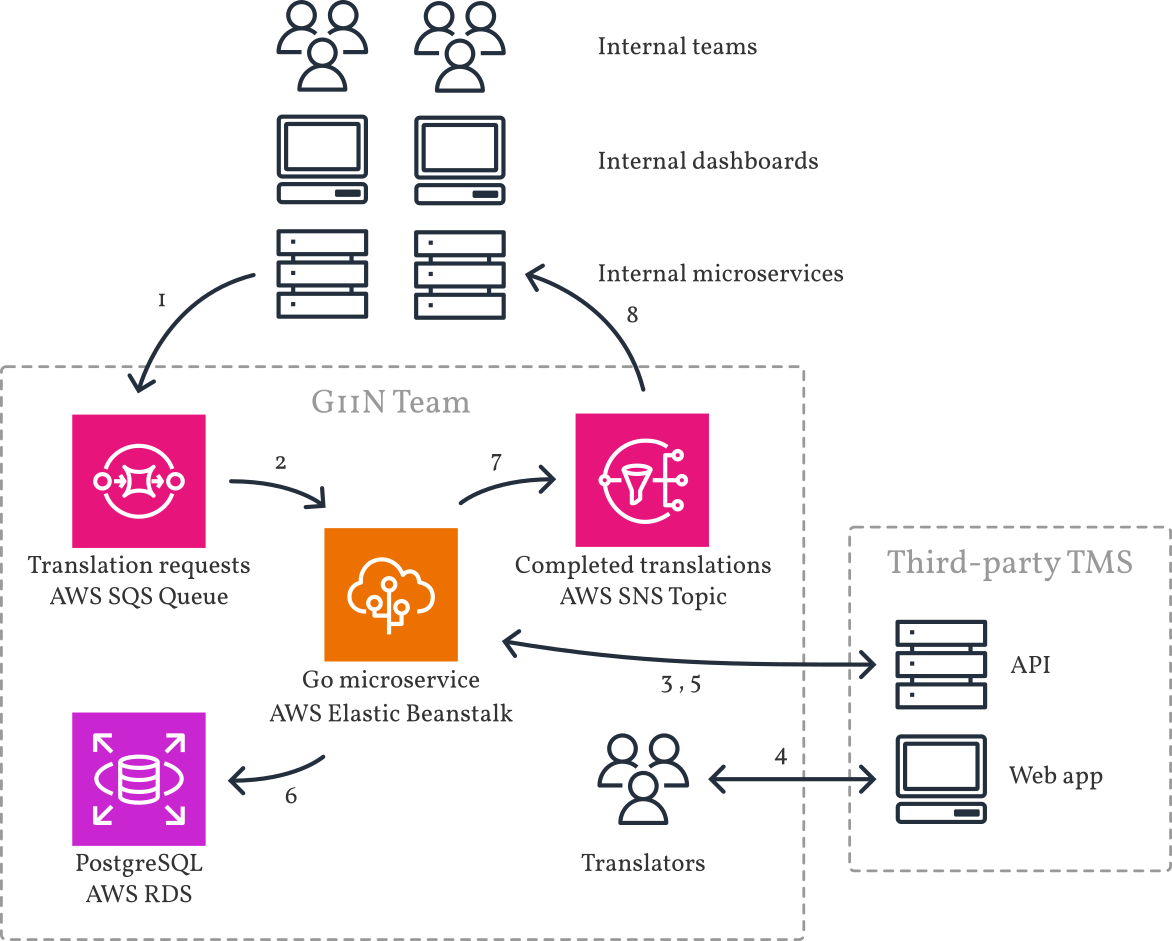
By using a messaging queue, we gain reliability for whenever the TMS has outages—and this has paid off, because our TMS regularly undergoes scheduled maintenance during which our system still accepts translations from the rest of Fetch’s teams. At the time of writing, Version 1 has been running for well over a year with very few tweaks needed to improve reliability.
Limitations
In the interest of limiting the scope of work to get the project launched, we knew Version 1 would have its limitations.
First and foremost, a team could submit only one string at a time per translation request, and it
had to be entirely human language—not structured data like JSON or YAML. Most teams, however,
needed multiple pieces of content to be grouped together: think title, subtitle, and description.
The compromise was for those teams to structure their string identifiers—called keys—in a
way that they could parse which
field it was when they received the completed translations. For example, they would send
item-id.title and item-id.subtitle as separate requests. When we sent back the
translations, they could split the key name on the dot to extract the ID and field name, and thus
determine the correct place to store the completed translation.
Second, submitting requests to SQS proved to be an awkward developer experience. I built validation into the client library because otherwise the developer would have no useful feedback about what was wrong with their request, if they even noticed at all. However, this also meant that whenever we wanted to change our validation requirements, we’d need to publish a new version of the client library and encourage teams to adopt it amongst their already busy schedules.
Third, once the request had been submitted, there was no way to programmatically edit or cancel it. Teams would have to reach out on Slack and describe the situation. This proved to be a much more frequent problem than we originally anticipated.
Version 2.0
Once the company had fully transitioned to support Spanish, our next mission was to identify friction points, reduce turnaround time, and generally improve translation workflows. I worked with the team lead to design improvements for the translation request system.
I began engineering a new system while keeping the original system running as to not interrupt any business-critical workflows. To address the limitations of Version 1, we introduced the concept of a translation job. A job, identified by a generated ID, could encapsulate multiple keys and strings. The job could be created with all of its keys, or keys could be added over time until the job was ready to submit.
To iterate quickly without disturbing the existing system, I decided to implement Version 2 as a separate microservice—and, based on metrics that indicated we were receiving at most a few hundred translation requests sporadically throughout the day, I decided to implement the service as an AWS Lambda with on-demand DynamoDB for persistent storage. This entirely serverless approach meant that we would only be charged for the short periods of time that we were processing translations throughout the day; in contrast, a service running in EC2 (like Version 1) would use dedicated server resources 24/7. The cold startup delay of Lambda wouldn’t be a problem because a few hundred milliseconds are negligible compared to the time it takes for human translators to draft, edit, and review.
Unlike Version 1, in which integrating teams needed to drop a message on an SQS queue, I decided that interaction with Version 2 would primarily be through a JSON API over HTTP. I configured an Application Load Balancer to trigger the Lambda for HTTPS traffic at the desired internal subdomain. Teams would be able to create, read, update, and cancel the job over the API. A full audit log would help us debug any translations that seemed to go missing or off schedule.
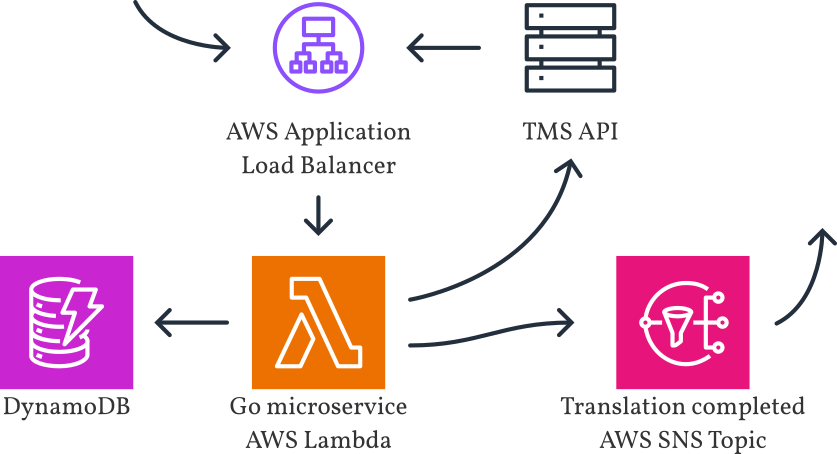
Ultimately, there are many edge cases in such a system: race conditions, temporary network errors, and rate limits imposed by the third-party API. One edge case of particular interest is when a team submits a job for a key that is actively undergoing translation in another job. We decided to reject the incoming job with a response indicating the ID of the job that was already translating the key. The integrating team could then choose to either cancel the old job or wait for it to complete. By ensuring our system knows when a key is actively being translated, we can prevent the source text from changing out from under our translators, thereby reducing churn and ensuring accurate translations.
Future Work
I have since moved to another team, but I look forward to seeing teams start to integrate with Version 2.0 as well as how the system continues to evolve.